
Na początku sierpnia przeprowadziłem analizę imion, które to najczęściej nadawane są naszym pociechom. Aby domknąć ten temat postanowiłem przyjrzeć się drugiemu członowi identyfikacyjnemu czyli nazwisku. Na początek należy stwierdzić, że z nazwiskiem sprawa jest nieco bardziej skomplikowana. Choćby z uwagi na to, że w przypadku kobiet nazwisko może mieć typowy męski oddźwięk. Nie ma chyba też idealnego algorytmu, który pozwoliłby na bezbłędne przekształcenie kobiecego nazwiska na męski odpowiednik. Stąd w przedstawionej poniżej analizie zostały uwzględnione jedynie męskie odmiany nazwisk. Dane do analizy, tak jak w przypadku analizy imion zostały pobrane ze strony Ministerstwa Cyfryzacji i za pomocą funkcji read.table() z pakietu utlis wczytane do środowiska R.
nazwiska.df <- read.table(textfile, quote = "", header = TRUE, fill = TRUE, sep = ",", stringsAsFactors = FALSE, encoding="UTF-8")
colnames(nazwiska.df) <- c('Wojewodztwo','Kod_TERYT','Nazwisko','Liczba_wystapien')
Sprawdźmy zatem na początek, które z nazwisk są najbardziej popularne. Dokonujemy grupowania danych według nazwiska, a następnie wyznaczamy procentowy udział nazwiska w męskiej części populacji.
nazwiska.df.pl <- nazwiska.df %>%
group_by(Nazwisko) %>%
summarise(
Liczba = sum(Liczba_wystapien)
)
nazwiska.df.pl.all <- as.integer(sum(nazwiska.df.pl$Liczba, na.rm = TRUE))
nazwiska.df.pl['procent'] <- nazwiska.df.pl['Liczba']/nazwiska.df.pl.all * 100
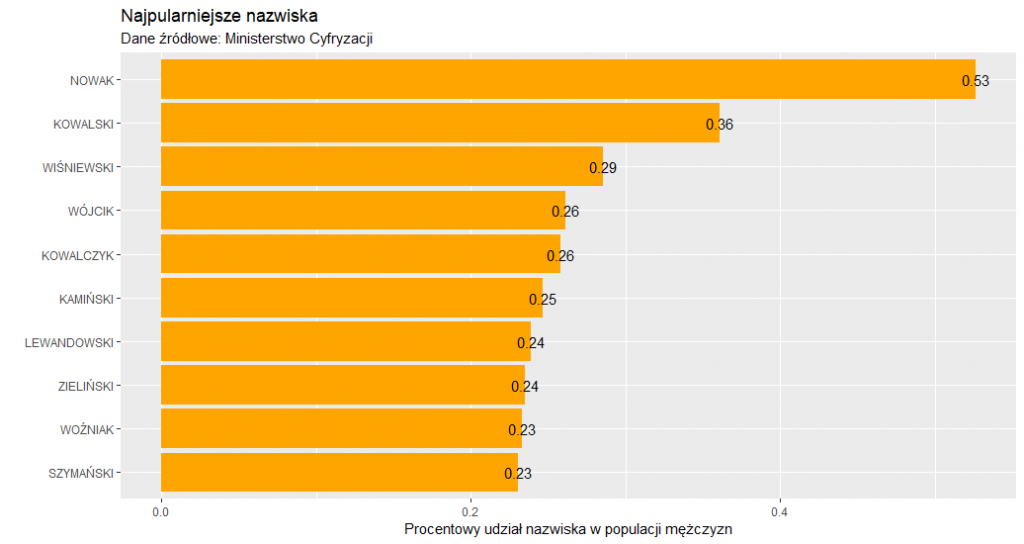
I cóż takiego możemy się dowiedzieć z powyższego wykresu. A to, że najpopularniejsze nazwisko w Polsce to Nowak. Nosi go jednak niewiele więcej niż 0,5% męskiej populacji. Zresztą nazwiska są znacznie bardziej rozrzedzone niż imiona, bo najpopularniejsze imiona są nadawne z blisko 5%-owym udziałem w populacji. Drugim w kolejności nazwiskiem typowym dla męskiej części populacji Polski jest Kowalski. Potem Wiśniewski, Wójcik itd. W gronie 10 najbardziej popularnych nazwisk, aż sześć kończy się na „ski”.
Aby dowiedzieć się jak sytuacja przedstawia się w każdym z województw z osobna obliczymy procent udziału dla każdego nazwiska.
nazwiska.df %>%
group_by(Kod_TERYT) %>%
summarise(
all = sum(Liczba_wystapien, na.rm = TRUE)
) -> nazwiska.df.woj
nazwiska.df <- left_join(nazwiska.df,nazwiska.df.woj,by = c('Kod_TERYT'))
nazwiska.df['procent'] <- nazwiska.df['Liczba_wystapien']/nazwiska.df['all']*100
Graficznie wygląda to tak:
ggplot() + geom_polygon(data=wojewodztwa_df.x, aes(long, lat, group = group, fill=Nazwisko), color="grey") + scale_fill_brewer(palette = "YlGnBu") + geom_text(data=nazwisko.df.woj.top1,aes(long,lat,label=napis),size=4,color="orange") + theme_void()
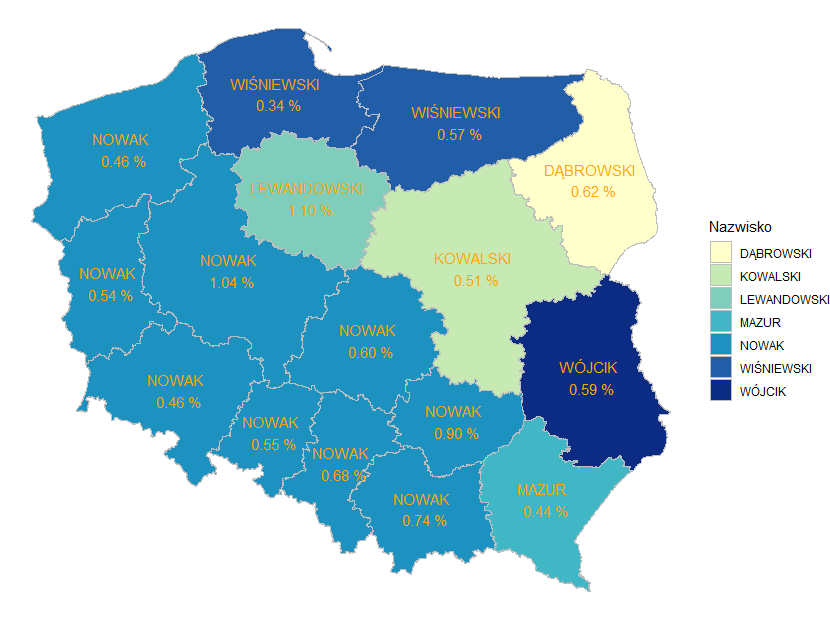
Podział jest widoczny. Pół Polski, a nawet więcej Nowakami „stoi” (praktycznie cała południowa i zachodnia Polska jest pod dominacją tego nazwiska). Na północy Polski (województwo pomorskie oraz warmińsko-mazurskie) dominuje klan Wiśniewskich. Z kolei część wschodnia ma swoje topowe nazwisko Dąbrowski w wojewódzwie podlaskim, oraz Wójcik w województwie lubelskim. W województwie mazowieckim dominuje Kowalski, a w kujawsko-pomorskim nazwisko Lewandowski.
A czy w poszczególnych województwach występują nazwiska, które są charakterystyczne tylko dla niego. Sprawdzamy.
library(knitr)
nazwisko.woj.single <- nazwiska.df %>% group_by(Nazwisko) %>% filter(n()==1)
nazwisko.woj.single %>%
group_by(Wojewodztwo) %>%
summarise(
ile = n()
) %>%
ungroup() %>% kable()
Jak się okazuje oczywiście występują typowe regionalizmy. Zaskoczeniem dla mnie była jednak dość spora ilość nazwisk, które występują tylko na terenie pojedynczego województwa. Zresztą spójrzmy na wynik.
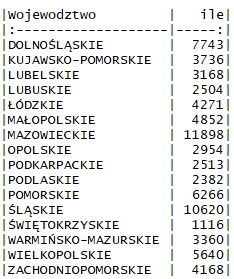
I tak np. w województwie śląskim mamy 10620 nazwisk, z którymi nie spotkamy się w żadnym innym województwie. Sprawdźmy jakie wśród tych nazwisk jest najpopularniejsze.
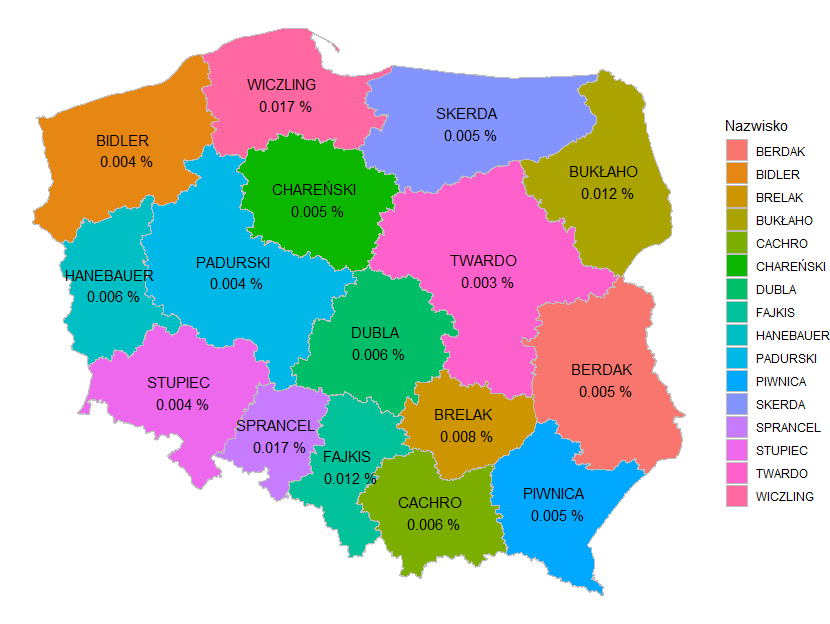
Podobnie jak wyżej również i tu podano procentowy udział danego nazwiska w populacji męskiej danego województwa. Najpopularniejsze nazwiska wśród regionalizmów charakteryzują się występowaniem na poziomie dziesięciotysięcznych procenta. Nazwisko Wiczling w województwie pomorskim oraz nazwisko Sprancel w województwie opolskim występuje w 1 na 5882 przypadku. Nazwisko Fajkis w województwie śląskim oraz Bukłaho w podlaskim z kolei pojawia się w 1 na 8333 przypadków.
Często też zastanawiamy się skąd pochodzi nasze nazwisko. Trzeba znowu przyznać, że sytuacja dla nazwisk jest dużo bardziej skomplikowana niż dla imion. Pochodzenie nazwisk nie jest zagadnieniem genealogicznym lecz antroponimicznym, związanym z językoznawstwem. Jak można przeczytać na blogu Przodek poznanie pochodzenia nazwisk jest trudniejsze niż odnalezienie przodków czy zbudowanie olbrzymiego drzewa genealogicznego, i w wielu przypadkach wymaga wielu godzin wręcz śledczego dochodzenia. Można o tym przeczytać tutaj. Autorowi bloga Przodek udało się odnaleźć pochodzenie dla określonej liczby nazwisk, ale sposób ich podania nie jest zbytnio uporządkowany. Stąd za pomocą poniższego kodu trochę to uporządkowałem. Wpisy zostały przesortowane w kolejności alfabetycznej, więc teraz łatwiej można odszukać potencjalne znaczenie swojego nazwiska. Tabela z linkami pod kodem:
library(rvest)
library(knitr)
GetLinksFromPage <- function(numer) {
page <- read_html(paste0("https://przodek.pl/genealogia/nazwiska/page/",numer))
#szukamy okreslonych wezłów i odczytujemy adres oraz tytuł z atrybutu
href <- page %>%
html_nodes("h3") %>% html_nodes("a") %>% html_attr("href")
title <- page %>%
html_nodes("h3") %>% html_nodes("a") %>% html_attr("title")
# pakujemy wszystkie linki w jedna ramke danych
nazwiska.df <- data.frame(nazwisko=title,link=href)
# przekazujemy ramkę danych do funkcji wywołującej
return(nazwiska.df)
}
links_list <- data.frame()
for (p in 1:13) {
links_list <- rbind(links_list,GetLinksFromPage(p))
}
Alfabetyczna tabela genealogii nazwisk:
| Nazwisko | Link |
|---|---|
| Anioł | link |
| Budny | link |
| Bartoszewski | link |
| Barcz, Bartel, Bartelik | link |
| Blok | link |
| Bigus, Bigos | link |
| Bęben, Bębenek, Bambenek | link |
| Bytów, Bytowski | link |
| Blumberg, Blumenberg | link |
| Begrow, Beggerow | link |
| Celejowski v. Celejewski h. Rawa | link |
| Czochra | link |
| Celejewski v. Celejowski | link |
| Czachorowski | link |
| Czachorowski | link |
| Czaja | link |
| Działoszyn | link |
| Dzianott de Castellati | link |
| Dymarek | link |
| Dułak | link |
| Damerau, Damerow | link |
| Früböse | link |
| Frankenstein | link |
| Gałązka (Galonska) | link |
| Gawliński | link |
| Grzenia, Grzenkowicz | link |
| Gruchała | link |
| Ginter, Gintrowski | link |
| Gosz, Gusz | link |
| Gustkow, Gostkowski | link |
| Hirsz/Hirsch | link |
| Hom(m)el, Czmiel, Trzmiel | link |
| Jeziorski/Jezierski h. Rogala | link |
| Jakubowski | link |
| Jarowicki | link |
| Jędernal, Jędernalik, Jędrnal, Jędrnalik | link |
| Jank, Janke, Janka | link |
| Jutrzenka, Morgenstern | link |
| Jażdżewski | link |
| Korosteński/Korostyński | link |
| Kania | link |
| Kądziela | link |
| Karwatka | link |
| Koniński | link |
| Kowalkowski | link |
| Klin | link |
| Knitter, Knetter | link |
| Klepin, Klepiński | link |
| Kosznik, Kośnik | link |
| Kusow, Kusowski, Kuszow, Kuszowski | link |
| Kolberg | link |
| Kukowski | link |
| Lipnicki | link |
| Leciej | link |
| Leszczyński | link |
| Lipowicz | link |
| Lepak | link |
| Lubenau, Lubow | link |
| Lilwic, Lilwitz, Lüllewitze | link |
| Lok, Loka | link |
| Laska, Laski | link |
| Leczkow, Leczkowski, Leszkowski | link |
| Lietzau | link |
| Loll | link |
| Lic, Lica | link |
| Łangowski | link |
| Łag, Łaga | link |
| Mączka | link |
| Mastelarz | link |
| Maziarski | link |
| Metzger | link |
| Mikulski | link |
| Maciejewski | link |
| Matejewicz | link |
| Masa, Massow, Massowa | link |
| Mielewczyk, Młyński, Muński | link |
| Myszk, Myszka | link |
| Netreba | link |
| Naturalny | link |
| Obst | link |
| Ołpiński | link |
| Połupanówka | link |
| Poluchowicz | link |
| Połubiński | link |
| Putkowski | link |
| Page, Paga, Pagel | link |
| Pepliński, Pelpliński | link |
| Palberg, Palbach | link |
| Pomyski, Pomyjski | link |
| Piritz | link |
| Pomezański, Pomes, Pomazany | link |
| Polcyn, Polzin | link |
| Reszka | link |
| Romer | link |
| Rusiecki | link |
| Rudnik | link |
| Rostan, Rostanek, Rostank, Rostankowski | link |
| Szomański h. Jastrzębiec | link |
| Sarzyński | link |
| Sułów | link |
| Surchów | link |
| Susiec | link |
| Salutryński | link |
| Sieniawski | link |
| Skąpski | link |
| Skrzymowski | link |
| Sobisz, Sabisz | link |
| Steinhoff, Steinhofer, Steinow | link |
| Schaldach, Szaldach, Przybysz, Przybycień | link |
| Stojek, Stojke, Stojka | link |
| Suchy, Suchorz | link |
| Tomiński | link |
| Wojno h. Trąby | link |
| Wasylkowce | link |
| Wielącza | link |
| Wessel | link |
| Wiesiełowski/Wiesiołowski | link |
| Wysocki | link |
| Weiher, Wejher, Weier, Wajer | link |
| Witemberg | link |
| Zadarnowski | link |
| Zawada | link |
| Zbijewski | link |
| Ziegert, Cygert, Cygiert | link |

