
Najpierw pisaliśmy kartki wysyłane pocztą tradycyjną. Potem przyszła moda na smsy, kartki elektroniczne, emaile dziś komunikatory. Obojętnie jakim kanałem transmisji byśmy się jednak nie posłużyli to „clou” przesyłanej wiadomości stanowiła oczywiście jej treść. W większości przypadków, życzenia świąteczno-noworoczne to zazwyczaj standardowe formułki z tekstem „Wesołych Świąt”. Funkcjonują także krótkie wierszyki o różnym charakterze, które można znaleźć na wielu stronach internetowych. Jednak jest ich tak dużo, że czasem trudno wybrać lub zdecydować się by z jakiegoś skorzystać w imię podpowiedzi. Czy w takim razie sztuczna inteligencja (AI) mogła by nam służyć jakąś pomocą? Oczywiście. Dziś skorzystanie z „chatbota”, czy ogólnie mówiąc metod przetwarzania języka naturalnego (ang. natural language processing) wkracza do naszego życia wielkimi krokami, i to praktycznie w każdym jego aspekcie.
W tym przykładzie będę chciał zademonstrować działanie AI celem generowania treści życzeń na zbliżające się Święta Bożego Narodzenia, choć oczywiście zawsze te pisane od serca, osobiście tworzone, będą bezwzględnie najważniejsze.
GPT-3
W listopadzie 2021 laboratorium OpenAl, jedno z najlepszych ośrodków badawczych sztucznej inteligencji, uruchomiło usługę dostępu do opracowanego modelu językowego określonego jako GPT-3 (ang. generative pre-trained transformer model). Czym jest GPT-3? Tłumacząc wprost to model językowy zdolny do generowania nowego tekstu, wytrenowany na dużym zbiorze danych poprzez architekturę sieci głębokiego uczenia zwaną modelem transformatorowym. GPT-3 jest pierwszym w historii przetwarzania języka naturalnego uogólnionym modelem językowym, który może równie dobrze wykonywać szereg zadań przetwarzania języka naturalnego. Jego elastyczność w wykonywaniu serii uogólnionych zadań wiąże się z ogromną wydajnością i dokładnością. Zresztą zachęcam do wysłuchania wywiadu z Melanie Subbiah, która wraz ze swoim zespołem brała udział w opracowaniu tego niesamowitego modelu językowego. Opowiada ona o tym jak tworzony był ten model, jakie ma mocne strony, i wskazuje również te, które jeszcze wymagają dopracowania.
GPT-3 Playground
Zabawę z modelem GPT-3 najprościej rozpocząć od stworzonej przez OpenAI strony internetowej stanowiącej przysłowiowy „plac zabaw”. Tylko, aby się na tym placu pobawić musimy najpierw na platformie OpenAI utworzyć konto, i się na nim zalogować. Wówczas dopiero po zalogowaniu w pasku menu pojawia się zakładka Playground.
Trzeba jednak wiedzieć, że usługa jest płatna. Na start dostajemy jednak 18 USD do wykorzystania w okresie trzech miesięcy od daty utworzenia konta. Nie jest to mało z uwagi na to w jaki sposób naliczane są płatności za korzystanie z GPT-3.
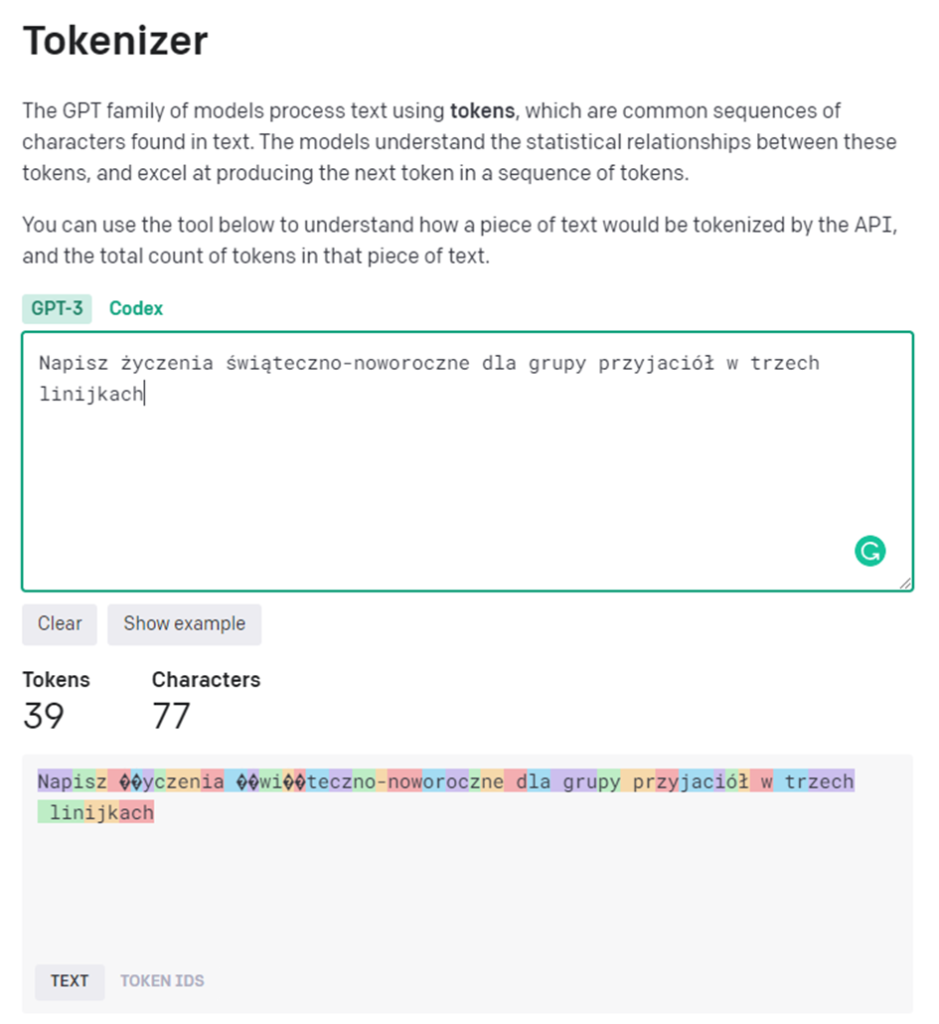
Po pierwsze wartość usługi naliczana jest na podstawie tzw. tokenów. Czym one są? Dla uproszczenia o tokenie możemy myśleć jako sylabie. Np. dla tekstu w języku angielskim 1 token to około 4 znaki lub 0,75 słowa. Aby sprawdzić ilość tokenów dla naszego sformułowanego zapytania można się posłużyć narzędziem Tokenizer. Jak widać z poniższego rysunku przykładowa podpowiedź dla GPT-3 to 39 tokenów.
Druga rzecz to model, z którego chcemy skorzystać. Mamy ich tu aż cztery. Są to modele nazwane odpowiednio : Ada, Babbage, Curie oraz Davinci. Każdy z nich na cześć wielkiego uczonego. Tak więc Ada na cześć Ady Lovelace, Babbage na cześć Charlesa Babbage, Curie oczywiście na cześć naszej Marii Sklodowskiej-Curie oraz Davinci na cześć Leonarda Da Vinci. Model Ada jest najszybszy, podczas gdy Davinci jest modelem najbardziej zaawansowanym. Różnica pomiędzy modelami opisana jest tutaj. Koszt skorzystania z wybranego modelu jest następujący:

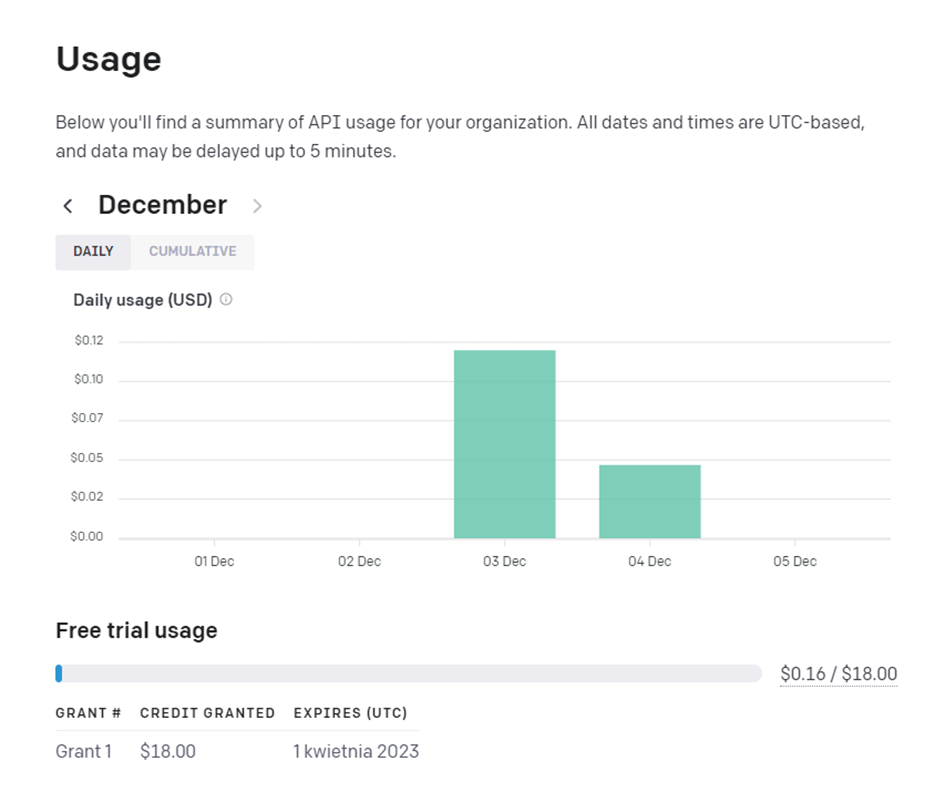
Najtańszym modelem jest Ada, najdroższym Davinci. Każde 1000 tokenów liczonych jako suma wprowadzonej do modelu GPT-3 informacji i uzyskanej w wyniku jego działania odpowiedzi jest liczona według podanych wyżej wartości. Zatem przy modelu Davinci kwota wstępnego wystarczy nam na 900 tokenów. W ramach konta mamy na bieżąco prowadzoną statystykę w postaci dziennego wykorzystania oraz skumulowanej sumy.
Teraz z pełną świadomością ewntualnych kosztów możemy wrócić na nasz plac zabaw. Chciałbym jeszcze tylko zwrócić uwagę na parametry, za pomocą których możemy sterować działaniem modelu GPT-3. Zlokalizowane są one po prawej stronie placu zabaw. Znajdziemy tu następujące parametry:
- Model – rodzaj modelu. Z rozwijanej listy wybieramy ten, który chcemy zastosować. Od razu mamy też krótki opis silnych stron modelu.
- Temperature – odpowiada za losowość odpowiedzi. Reprezentowana jako zakres liczba od 0 do 1. Niższa wartość parametru oznacza, że API odpowie pierwszą, jaką zobaczy model; wyższa wartość oznacza, że model ocenia możliwe odpowiedzi, które mogłyby pasować do kontekstu.
- Maximum length – określamy maksymalną liczba tokenów w wygenerowanej odpowiedzi.
- Stop sequences – do czterech sekwencji, gdzie API nie nalicza użytych tokenów. Wygenerowany przez model tekst nie będzie zawierał tych sekwencji.
- Top P – kontroluje, ile losowych wyników model powinien rozważyć, zgodnie z sugestią parametru temperatury, określając w ten sposób zakres losowości. Zakres Top P zawiera się w przedziale od 0 do 1. Niższa wartość ogranicza kreatywność modelu GPT-3, natomiast wyższa rozszerza ją.
- Frequency penalty – kara częstotliwości zmniejsza prawdopodobieństwo, że model powtórzy ten sam wiersz
- Presence penalty – kara obecności zwiększa prawdopodobieństwo, że w odpowiedzi poruszane będą nowe tematy.
- Best of (n) – pozwala określić liczbę uzupełnień wygenerowanych po stronie serwera i zwrócić najlepsze n. Przesyłanie strumieniowe działa tylko przy wartości 1. Ważne, parametr ten jest mnożnikiem także trzeba z nim uważać gdyż będzie mnożył również tokeny.
- Inject start & restart text – parametry pozwalają na wstawienie tekstu odpowiednio na początku i na końcu uzupełnienia
- Show probabilities – opcja służąca do kontroli podpowiedzi tekstowej poprzez pokazanie prawdopodobieństwa tokenów, które model może wygenerować dla danego wejścia.
To do dzieła. Na początku wprowadzamy tekst stanowiący zachętę (ang. prompt) dla modelu. Jest on istotny, bo to właśnie na jego podstawie model będzie generował tekst wyjściowy (ang. completion). Stąd zachętę, podpowiedź należy sprecyzować tak, aby dać modelowi wystarczająco dużo kontekstu, w którym tworzona przez niego treść odpowiedzi będzie, jego zdaniem, najlepszym uzupełnieniem danych wejściowych. Nie powinno się z jednej strony ani przeładowywać modelu informacjami, ale z drugiej podanie zbyt małej ilości może prowadzić do niedokładnych wyników. Pamiętajmy, że teoretycznie GPT-3 nie wspiera języka polskiego, a jednak rezultat może zaskakiwać. Tak, odpowiedź modelu to ta część podświetlona na zielono.
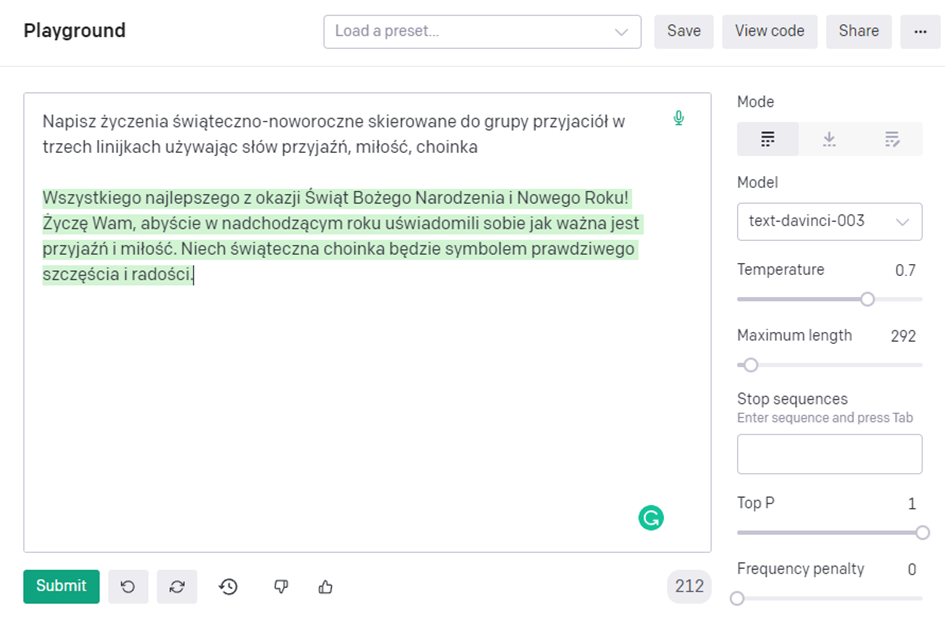
Można być pod wrażeniem prawda. Zresztą nie tylko ja jestem. Tu choćby przykład: Cyberiada, wiersze i generowanie aplikacji za pomocą AI.
Życzenia świąteczno-noworoczne pisane przez GPT-3 w Jupyter
Korzystanie z placu zabaw to oczywiście nie jedyna droga skorzystania z GPT-3. Jak wspomniałem OpenAl udostępnił programistom interfejs API w listopadzie 2021 r. I wtedy się zaczęło. W ciągu roku, jak można odczytać na stronie OpenAI, API zostało wdrożone w tysiącach aplikacji wykonujących zadania począwszy od pomocy ludziom w nauce języków obcych aż po rozwiązywanie złożonych problemów klasyfikacyjnych.
Poniżej przedstawię jak można zadanie służące do generowania życzeń świąteczno-noworocznych przeprowadzić w środowisku Jupytera. Pierwszą rzeczą jest oczywiście zainstalowanie, a potem wczytanie biblioteki openai. Z kolei by skorzystać z modelu GPT-3 potrzebujemy klucz API. Generujemy go na naszym koncie w OpenAI pod zakładką API Keys. Po wczytaniu klucza API definiujemy parametry modelu GPT-3 i przygotowujemy podpowiedź (prompt) dla modelu. Pamiętajmy o odpowiednio przygotowanym kontekście tej podpowiedzi.
Poniżej kod i przykłady kilku wygenerowanych przez model GPT-3 życzeń skierowanych do osób docelowych
Dla rodziny:
Życzę Wam zdrowia i szczęścia w nadchodzącym Nowym Roku oraz pogody ducha podczas rodzinnych spotkań przy szczególnie urodziwej choince.
Dla przyjaciela:
Życzę Ci zdrowia, szczęścia i pogody ducha w Nowym Roku. Niech choinka będzie dla Ciebie źródłem radości i niech wszystkie Twoje marzenia się spełnią.
Dla szefa:
Życzę Panu zdrowia i szczęścia w Nowym Roku, i aby się dzielnie Pan zmagał z wszelkimi wyzwaniami. Niech pogoda ducha i blask choinki przynoszą Panu radość i wieczny optymizm.
Prawda, że praktycznie nie ma się do czego doczepić 😊. A ponieważ do Świąt Bożego Narodzenia pozostało jeszcze kilkanaście dni, stąd dla Państwa jeszcze życzeń nie mam. Z pewnością będą, acz tajemnicą niech będzie czy wygenerowane przez GPT-3 czy złożone prosto z serducha. Kto przeczytał uważnie pierwszy akapit ten z pewnością już wie.