
Ostatnia dekada w informatyce należy z pewnością do dziedziny, którą określa się jako uczenie maszynowe (ang. machine learning) i traktuje tę dziedzinę jako rodzaj sztucznej inteligencji, która z surowych danych wyodrębnia określone wzorce korzystając z przygotowanego algorytmu lub metody.
System komputerowy uczy się, a następnie może być zdolny do podejmowania decyzji, tam gdzie np. brakuje ludzkiej wiedzy, dane szybko się zmieniają czy występuje wręcz trudność w przełożeniu wiedzy specjalistycznej na zadania obliczeniowe. Wtedy „wyuczony” odpowiednio system komputerowy może być nieocenioną pomocą.
Jak zatem nauczyć system komputerowy realizacji postawionego przed nim zadania? Należy przeprowadzić pewien cykl działań, który może być przedstawiony jako następujący ciąg:
- Pozyskanie danych (Data Collection)
- Przygotowanie danych (ang. Data Preprocessing)
- Tworzenie zmiennych (Feature Engineering)
- Wybór zmiennych (Feature selection)
- Budowa modelu (Model Building)
- Optymalizacja parametrów modelu (Hyperparameter tuning)
- Wdrożenie modelu (Model Deployment)
Przygotowanie danych (ang. data preprocessing)
W tej serii wpisów skupię się na drugim elemencie z podanej listy, czyli na przygotowaniu danych. Odnoszę bowiem takie wrażenie, analizując metody uczenia metod uczenia maszynowego, że temu elementowi poświęca się zbyt mało czasu. A, zacznę od truizmu, przygotowanie danych jest niezwykle ważnym elementem w całym cyklu uczenia maszynowego. Ale czy mogłoby być inaczej skoro stare powiedzenie funkcjonujące w obszarze technologii informacyjnych ostrzega wprost: śmieci weszły, śmieci wyszły (ang. garbage in, garbage out). A skoro algorytmy czy metody uczenia maszynowego są całkowicie zależne od danych, które do nich wprowadzimy, to jeżeli odpowiednio się do tego nie przyłożymy by te dane przygotować dla problemu, który chcemy rozwiązać, to w efekcie rozwiązanie może okazać się bezużytecznym.
Stąd też wstępne przygotowanie danych, rozumiane jako ich przekształcenie, zgodne z oczekiwaniem algorytmu uczenia maszynowego, jest moim zdaniem (i pewnie nie tylko 😊 ) najważniejszym krokiem w procedurze uczenia maszynowego. Stąd też postaram się przybliżyć ten krok. Będę do tego potrzebował kilka wpisów. Dlaczego? Dlatego, że obecnie zagadnienie przygotowania danych (ang. data preprocessing) jest już całkiem szeroko rozbudowanym obszarem wiedzy, gdzie mamy do czynienia z takimi czynnościami jak:
- radzenie sobie z brakującymi danymi,
- kodowanie zmiennej, ze szczególnym uwzględnieniem zmiennej kategorialnej,
- transformacje w kierunku rozkładu normalnego zmiennej,
- dyskretyzacja zmiennej oraz
- skalowanie zmiennej.
Rodzaje zmiennych
Zanim przejdę do przedstawienia wymienionych wyżej zagadnień to dziś jako wstęp proszę potraktować omówienie słowa, które niejednokrotnie przy wymienianiu powyższych czynności procesowych się pojawiło. Mowa o „zmiennej”. Pojęcie to z pewnością dobrze jest znane statystykom, którzy zazwyczaj w pierwszej kolejności zmienne dzielą na: ilościowe i jakościowe. Zmienna ilościowa może zostać zmierzona i ma określoną wartość liczbową. A zmienną, która nie jest ilościowa przyjmują jako jakościową.
W uczeniu maszynowym zmienne te określane są mianem liczbowych (ilościowe) i kategorycznych (jakościowe).
Przykładowo, do zmiennych liczbowych można zaliczyć: wzrost (wyrażony w jednostce miary), wiek (wyrażony w latach), waga (wyrażona w jednostce miary) itp. Z kolei do zmiennych kategorycznych zaliczymy te zmienne, które opisane są przez ograniczoną liczbę potencjalnych wartości, tzw. kategorii. Kategorie nie mają kolejności, nie mogą być uporządkowane od najwyższej do najniższej. Jak to? Przecież możemy np. kategorie uszeregować. Choćby zmienna kategoryczna reprezentująca wykształcenie, której kategorie (w uproszczeniu) takie jak:
- podstawowe,
- średnie,
- wyższe
możemy uszeregować w podanej kolejności. No właśnie taka drobna różnica pomiędzy uszeregowaniem, a liczbowym uporządkowaniem. Powiedzmy zatem tak, że mamy zmienne kategoryczne porządkowe (które da się uszeregować) i nominalne (które, nie da się uszeregować). A wśród zmiennych ilościowych moglibyśmy wyróżnić zmienne ciągłe i dyskretne.
Przyjdzie nam jeszcze, przy analizie zmiennej, spotkać się ze zmienną mieszaną, czyli taką która będzie zawierać zarówno liczbę jak i etykietę kategorii. Przykładem może być tablica rejestracyjna samochodu, gdzie mamy znaki i cyfry, często identyfikator biletu na jakieś wydarzenie sportowe bądź muzyczne, czy np. identyfikator pokoju w hotelu. I oczywiście nie możemy zapomnieć o zmiennej określającej datę i czas.
Wymienione zmienne kształtują zbiór zmiennych, z którymi przyjdzie nam się spotkać. Zerknijmy zresztą jak to wygląda na jakichś przykładowych danych.
Przykład
Skorzystam z danych zamieszczonych na stronie Analyze Boston [1], miejskiego serwisu miasta Boston. Po prostu zazdroszczę Amerykanom tak szerokiego, publicznego dostępu do szeregu różnorodnych danych.
W tym zakresie polskie miasta, samorządy mają wiele do nadrobienia. I działania państwa w tym zakresie też trzeba uznać za niewystarczające, choć są pozytywne (https://www.gov.pl/web/cyfryzacja/otwarte-dane-publiczne).
Interesować mnie będą, a jakże, dane dotyczące zużycia nośników energii w nieruchomościach zamieszkałych i niezamieszkałych. Taki pakiet danych można znaleźć pod linkiem [2], gdyby ktoś także chciał do niego sięgnąć. Dane za 2021 zapisane są w formacie Excela.
Zatem wczytajmy dane do środowiska Jupyter Notebook za pomocą metody read_excel z biblioteki pandas. Następnie korzystając z atrybutu dtypes przeanalizujmy rodzaje zmiennych, które w tym zbiorze występują.
import pandas as pd
df = pd.read_excel('2021-reported-energy-and-water-metrics.xlsx')
df.dtypes
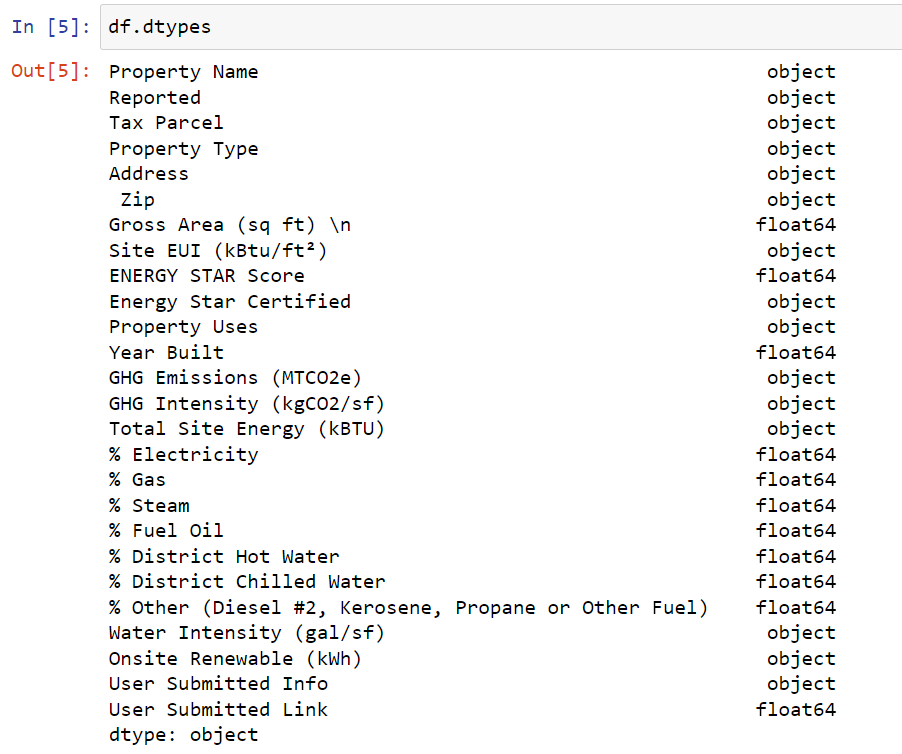
Jak widać, w zbiorze mamy dwa typy danych: float64 oraz object. Typ danych float64 reprezentuje zmienną liczbową zmiennoprzecinkową, podczas gdy typ object zmienną kategoryczną. W praktyce spotkamy się jeszcze z typem int64 reprezentującym liczby całkowite, datetime64, który w Pythonie reprezentuje zmienną daty i czasu oraz bool jako typ zmiennej logicznej.
Zresztą aby to zaprezentować posłużę sie przykładem z dokumentacji biblioteki pandas.
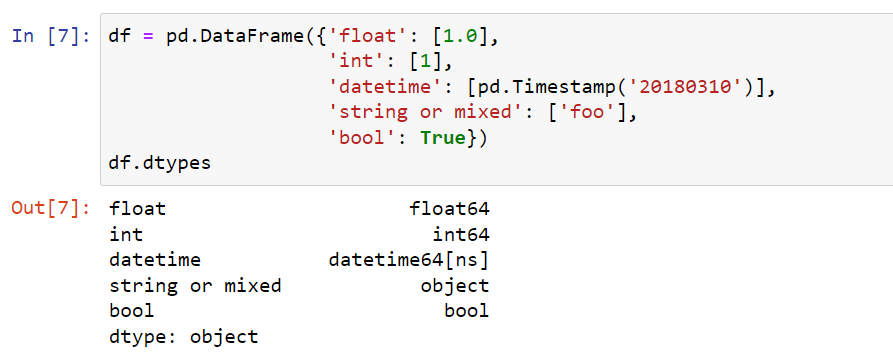
Dla zainteresowanych polecam także artykuł Overview of Pandas Data Types – Practical Business Python (pbpython.com)
[1] Welcome – Analyze Boston[2] Building Energy Reporting and Disclosure Ordinance (BERDO) – 2021 Reported Energy and Water Metrics – Analyze Boston


