
Od wersji 0.9.1 biblioteki pvlib-python zaprzestano prac nad rozwijaniem modułu prognozowania uzysku energii elektrycznej z instalacji fotowoltaicznej opartego na danych pogodowych pochodzących z szerokiej gamy modeli pogodowych. Niestety, interfejs API dostępu do modeli uległ zmianie, a nie znaleziono chętnych do poświęcenia czasu na dostosowanie modułu pvlib.Forecast. Jednakże, nie oznacza to, że nie można skorzystać z dotychczasowych osiągnięć w tym zakresie i dalej cieszyć się możliwością wykorzystywania dostępnych w Unidata prognoz opartych na modelach NOAA/NCEP/NWS (National Centers for Environmental Prediction), w tym GFS (Global Forecast System). I o tym jest ten wpis, czyli jak sobie radzić by na podstawie prognozy pogody z NCEP uzyskać informacje o możliwym do osiągnięcia uzysku energii elektrycznej z naszej instalacji fotowoltaicznej.
Model GFS
Model GFS ( Global Forecast System) nie został wybrany przypadkowo, gdyż, jak sama nazwa wskazuje, ma on zasięg globalny, obejmujący także prognozę dla Polski. Ogólnie rzecz biorąc, GFS dostarcza globalne prognozy atmosferyczne i falowe o rozdzielczości 13 km. Jest uruchamiany cztery razy dziennie i pozwala na generowanie prognozy w trzygodzinnych odstępach do 10 dni oraz z 12-godzinnym odstępem w przypadku 10-16 dniowej prognozy. Więcej informacji na temat modelu GFS można znaleźć na jego stronie.
Dane modelu GFS (ale nie tylko jego) są gromadzone w katalogu Unidata THREDDS. W katalogu Forecast Model Data można znaleźć szereg prognoz opracowanych w różnych modelach i z różną rozdzielczością przestrzenną. Obecnie interesuje nas pozyskanie prognozy pogody dla najbliższych 7 dni w półstopniowym modelu GFS.
W modelu zapisywana jest ogromna ilość informacji – obejmuje 170 różnych zmiennych. Dla celów prognozowania uzysku energii z instalacji fotowoltaicznej nie potrzebujemy wszystkich zmiennych, skoncentrujemy się jedynie na następujących:
Temperature_surface,
u-component_of_wind_isobaric,
v-component_of_wind_isobaric,
Total_cloud_cover_entire_atmosphere_Mixed_intervals_Average ,
Low_cloud_cover_low_cloud_Mixed_intervals_Average,
Medium_cloud_cover_middle_cloud_Mixed_intervals_Average,
High_cloud_cover_high_cloud_Mixed_intervals_Average,
Total_cloud_cover_boundary_layer_cloud_Mixed_intervals_Average,
Total_cloud_cover_convective_cloud
Zmienne przedstawiają temperaturę otoczenia, składowe wiatru do wyznaczenia jego prędkości oraz informacje o stopniu pokrycia nieba przez chmury (więcej: https://study.com/learn/lesson/cloud-cover-effects-weather.html)
Aby ułatwić dostęp do tych danych, Unidata opracowała bibliotekę o nazwie siphon, umożliwiającą programowy dostęp do danych THREDDS. Zatem zabierajmy się do pracy!
Prognoza pogody z THREDDS
Na początku odczytujemy odpowiedni katalog, korzystając z metody TDSCatalog(). Następnie wybieramy zbiór danych, w tym przypadku „Best GFS Half Degree Forecast Time Series”, i za pomocą metody subset() otwieramy zdalny dostęp do danych.
W dalszej części przygotowujemy żądanie do usługi NCSS, aby pobrać dane wyżej wymienionych zmiennych, oczywiście dodatkowo określamy położenie geograficzne, wysokość nad poziomem morza oraz okres, dla którego będziemy prognozować. W ten sposób tworzymy ramkę danych df.
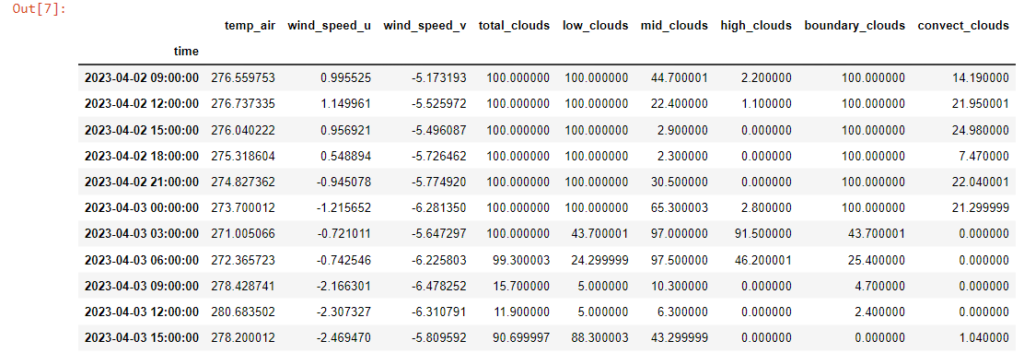
Obecnie dokonam zamiany prognozowanego stopnia pokrycia nieba przez chmury na prognozę składowych promieniowania, bo jak widać takich informacji bezpośrednio w strukturze danych prognozy pogodowej nie znajdziemy. W tym celu skorzystam z opracowanego w ramach istniejącego modułu pvlib.forecast kodu, który lekko zmodyfikowałem. Całość kodu znajduje się na serwerze Github.
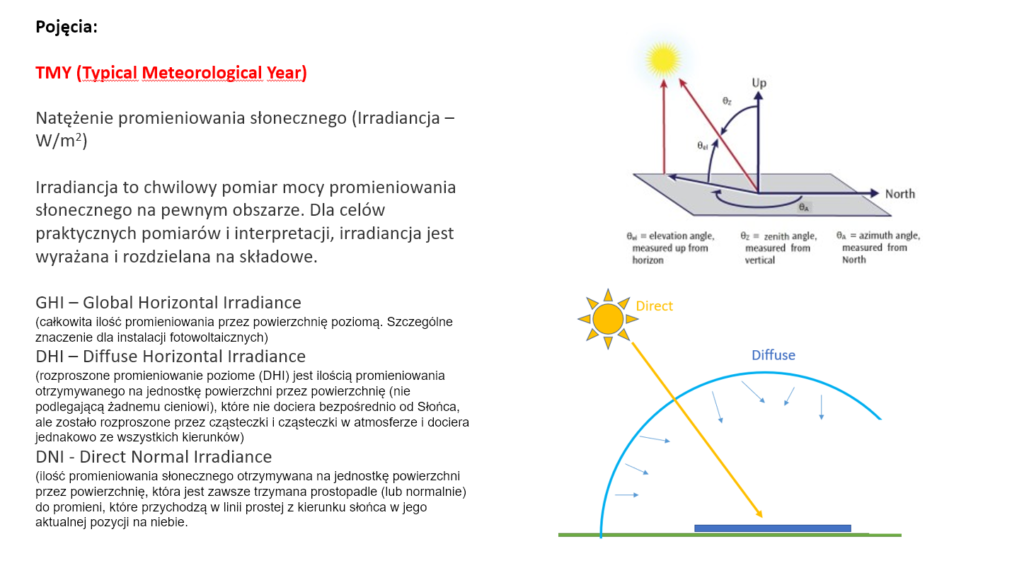
Biblioteka pvlib-python zapewnia dwa podstawowe sposoby konwertowania prognoz zachmurzenia na prognozę natężenia promieniowania. Jedna metoda zakłada liniową zależność między zachmurzeniem a GHI (Global Horizontal Irradiance), czyli stosuje skalowanie do klimatologii bezchmurnego nieba, a następnie wykorzystuje model DISC do obliczenia DNI (Diffuse Horizontal Irradiance). Druga metoda zakłada liniową zależność między zachmurzeniem a transmitancją atmosferyczną, a następnie wykorzystuje model Campbella-Normana do obliczenia składowych GHI, DNI i DHI [1]. Campbell-Norman jest przybliżeniem modelu Liu-Jordana [2].
Dla lepszego zrozumienia składowych GHI, DNI oraz DHI zamieszczam poniższy slajd z zajęć prowadzonych dla studentów kierunku „Odnawialne źródła energii” realizowanych przeze mnie na Politechnice Częstochowskiej, Wydział Infrastruktury i Środowiska.”
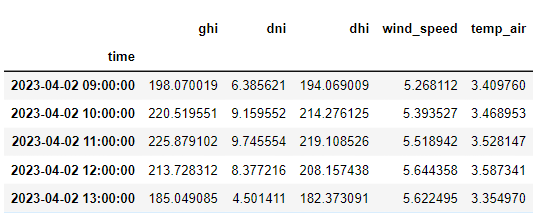
Wracając jeszcze na chwilę do naszego zbioru danych proszę zwrócić uwagę, że model generuje dane z 3-godzinną rozdzielczością czasową. Jeżeli zatem chcemy uzyskać ciut więcej to już te prognozowane dane musimy interpolować, i tym samym godzić się na pewne błędy związane z tym procesem. Niemniej za pomocą funkcji interpolate() z biblioteki pandas łatwo jest to zrobić i interpolować prognozę zachmurzenia nieba na dziedzinę czasu o większej rozdzielczości.
W wyniku interpolacji z rozdzielczością godzinową uzyskujemy dane, w oparciu o które przenalizuje uzysk energii z instalacji fotowoltaicznej.
Ale zrobię to przy okazji następnego wpisu. Będę miał wówczas możliwość porównać otrzymane dziś prognozy składowych GHI, DNI, DHI z wartościami rzeczywistymi.
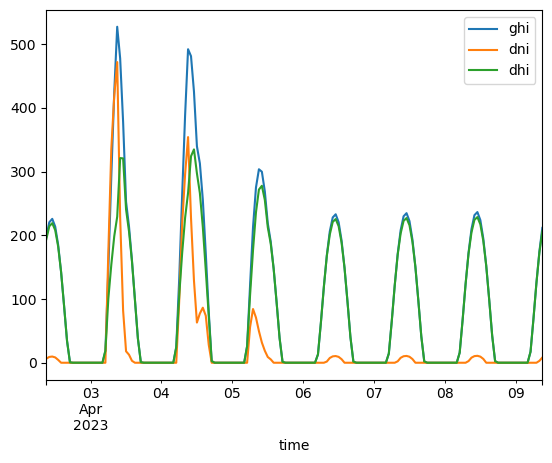
Na koniec jeszcze grafizcne przedstawienie prognozowanych składowych natężenia promieniowania słonecznego.
Odnośniki
- Campbell, G. S., J. M. Norman (1998) An Introduction to Environmental Biophysics. 2nd Ed. New York: Springer
- B. Y. Liu and R. C. Jordan, The interrelationship and characteristic distribution of direct, diffuse, and total solar radiation, Solar Energy 4, 1 (1960)
- Downloading model fields with NCSS



