
Od pewnego czasu na stronach Ministerstwa Cyfryzacji można znaleźć informacje o najpopularniejszych imionach, jakie rodzice nadawali swoim nowonarodzonym pociechom w określonym roku w Polsce. Jest to ciekawe zestawienie, gdyż można zorientować się jakie imiona były czy są popularne i jaka jest ich powtarzalność.
Jedyny problem to, że Ministerstwo nie usystematyzowało sposobu podawania tych danych. Praktycznie w każdym roku, począwszy od 2013 r., sposób przekazania tych informacji to pliki w różnych formatach, w różnych układach czy tak jak w 2018 roku wprost dane podane zostały bezpośrednio na stronie internetowej ministerstwa jako osobna podstrona dla każdego województwa w podziale na płeć. W związku z tym należało wszystkie dane zebrać, połączyć i uporządkować. Najciekawszym etapem tych prac był scrapping stron internetowych ministerstwa. Dla zainteresowanych przygotowany kod, oczywiście w środowisku R, podałem na końcu niniejszego wpisu. Z kolei plik wynikowy jest do pobrania celem samodzielnych analiz.
W tym miejscu zabierzmy się za analizę zgromadzonego materiału. Wczytujemy go zatem do środowiska R.
imiona.df <- read.table("imiona.txt", header=TRUE, encoding="UTF-8")
imiona.df$imie <- as.character(imiona.df$imie)
W efekcie mamy utworzony obiekt DataFrame (ramka danych) z 37236 wierszami reprezentującymi statystykę ilościową imion nadanych dzieciom urodzonych w latach 2013-2018 w podziale na płeć oraz województwa. Do pełni szczęścia brakuje jedynie tych danych, dla których wystąpienie imienia w danym roku było jednokrotne. Z uwagi na ochronę danych osobowych Ministerstwo Cyfryzacji tych danych nie podaje, choć trzeba zaznaczyć, że w latach 2015-2016 ograniczyło się do podania jedynie tych imion, które wystąpiły w ilości większej niż cztery.
Przedstawmy zatem te imiona, które cieszyły się największą popularnością w okresie ostatniego pięciolecia. Skorzystam z kodu rozdzielającego dane na grupę dziewczynek i chłopców, wybiorę dla każdego rocznika sześć topowych imion, a następnie wyświetlę je w postaci gotowego kodu html. W tym celu wykorzystam funkcję kable() z biblioteki knitr.
library(knitr)
imiona.df %>%
filter(plec == 'dziewczynek') %>%
group_by(rok,imie) %>%
summarise(
all = sum(liczba)
) %>%
arrange(desc(rok),desc(all)) -> TopGirlsAllYears
TopGirlsList = split(TopGirlsAllYears, TopGirlsAllYears$rok)
TopHeadGirls <- lapply(TopGirlsList, head)
TopHeadGirls <- do.call(rbind,TopHeadGirls)
imiona.df %>%
filter(plec == 'chlopcow') %>%
group_by(rok,imie) %>%
summarise(
all = sum(liczba)
) %>%
arrange(desc(rok),desc(all)) -> TopBoysAllYears
TopBoysList = split(TopBoysAllYears, TopBoysAllYears$rok)
TopHeadBoys <- lapply(TopBoysList, head)
TopHeadBoys <- do.call(rbind,TopHeadBoys)
TopHead <- arrange(cbind(TopHeadGirls,TopHeadBoys),desc(rok))[,-c(1,4)]
kable(TopHead,
col.names = c('Imię dla dziewczynki','Ilość - ranking ogólnopolski','Imię dla chłopca','Ilość - ranking ogólnopolski'),
format = "html")
W rezultacie:
| Imię dla dziewczynki | Ilość – ranking ogólnopolski | Imię dla chłopca | Ilość – ranking ogólnopolski |
| Rok 2018 | |||
|---|---|---|---|
| ZUZANNA | 8862 | ANTONI | 9325 |
| JULIA | 8463 | JAKUB | 8905 |
| MAJA | 8027 | JAN | 8455 |
| ZOFIA | 7928 | SZYMON | 8234 |
| HANNA | 7718 | ALEKSANDER | 7323 |
| LENA | 7647 | FRANCISZEK | 7093 |
| Rok 2017 | |||
| JULIA | 9397 | ANTONI | 9811 |
| ZUZANNA | 9203 | JAKUB | 9119 |
| ZOFIA | 8454 | JAN | 8559 |
| LENA | 8311 | SZYMON | 8148 |
| MAJA | 8075 | FRANCISZEK | 6963 |
| HANNA | 7936 | FILIP | 6941 |
| Rok 2016 | |||
| ZUZANNA | 8859 | ANTONI | 9216 |
| JULIA | 8667 | JAKUB | 8974 |
| LENA | 8386 | SZYMON | 8299 |
| MAJA | 8329 | JAN | 7627 |
| HANNA | 7969 | FILIP | 6691 |
| ZOFIA | 7731 | FRANCISZEK | 6562 |
| Rok 2015 | |||
| ZUZANNA | 9151 | JAKUB | 8730 |
| LENA | 8768 | ANTONI | 7988 |
| JULIA | 8541 | SZYMON | 7553 |
| MAJA | 8092 | JAN | 7271 |
| ZOFIA | 7380 | FILIP | 6801 |
| HANNA | 6940 | KACPER | 6479 |
| Rok 2014 | |||
| LENA | 10570 | JAKUB | 10165 |
| JULIA | 9603 | KACPER | 7877 |
| ZUZANNA | 9566 | ANTONI | 7715 |
| MAJA | 8842 | FILIP | 7640 |
| ZOFIA | 7176 | JAN | 7367 |
| HANNA | 6989 | SZYMON | 6510 |
| Rok 2013 | |||
| LENA | 11380 | JAKUB | 10810 |
| JULIA | 11209 | KACPER | 8590 |
| ZUZANNA | 9626 | FILIP | 8049 |
| MAJA | 9264 | SZYMON | 7092 |
| ZOFIA | 6668 | JAN | 7004 |
| AMELIA | 6449 | ANTONI | 6669 |
Jeżeli przyjrzeć się uzyskanym wynikom to widać, że preferencje wśród imion nadawanym dzieciom są raczej stabilne. Wśród imion dla dziewczynek prym wiodą Zuzanna, Julia oraz Maja. Lena, która na początku okresu analizy (lata 2013-2014) była liderem zestawienia powoli traci w rankingu. Z kolei wśród chłopców dominują imiona Jakub i Antoni. Kacper, który jeszcze w 2013-2014 był w czołówce rankingu wypadł poza pierwszą szóstkę. Zastąpił go Franciszek.
Najbardziej popularne imiona nadawane dziewczynkom i chłopcom w 2018r.


Zresztą aby mieć pełny obraz zmian pomiędzy poszczególnymi latami warto przeanalizować procentowe zmiany jakie wystąpiły dla danego imienia. Szkopuł jednak w tym, że dla imienia które występuje rzadko już zmiana np z dwóch wystąpień na cztery to zmiana 100%-owa. Dlatego analizę przeprowadziłem wyróżniając dwie grupy, pierwsza określona jako:
- grupa A – to grupa, gdzie liczba wystapień była większa niż 200 (ok 0,1% całej rocznej populacji) a mniejsza niż 1000 wystąpień
- grupa B – to grupa, w której liczba wystąpień przekraczała 1000 wystąpień.
# wzrost popularności imienia pomiędzy 2017 a 2018
TopGirlsAllYears %>%
spread(rok,all) %>%
set_names('Imie','R2013','R2014','R2015','R2016','R2017','R2018') %>%
select(-c('R2013','R2014','R2015','R2016')) %>%
filter(R2018 > 200 & R2018 < 1000) %>%
mutate(zmiana = (R2018-R2017)/R2017*100) %>% arrange(desc(zmiana)) %>% top_n(10) -> TopGirlsNameChangeLess
TopGirlsAllYears %>%
spread(rok,all) %>%
set_names('Imie','R2013','R2014','R2015','R2016','R2017','R2018') %>%
select(-c('R2013','R2014','R2015','R2016')) %>%
filter(R2018 >= 1000) %>%
mutate(zmiana = (R2018-R2017)/R2017*100) %>% arrange(desc(zmiana)) %>% top_n(10) -> TopGirlsNameChangeMore
plot1 <- TopGirlsNameChangeLess %>%
arrange(zmiana) %>%
mutate(Imie = fct_inorder(Imie)) %>%
ggplot(aes(Imie, zmiana)) +
geom_col(fill="orange") +
geom_text(aes(label=R2018)) +
coord_flip() +
labs(title = "Wzrost popularności imienia dla dziewczynki",
subtitle = "Porównanie: 2018/2017 (2017 = 100%) (grupa A)",
x = "", y = "Procentowa zmiana popularności imienia")
plot2 <- TopGirlsNameChangeMore %>%
arrange(zmiana) %>%
mutate(Imie = fct_inorder(Imie)) %>%
ggplot(aes(Imie, zmiana)) +
geom_col(fill="orange") +
geom_text(aes(label=R2018)) +
coord_flip() +
labs(title = "Wzrost popularności imienia dla dziewczynki",
subtitle = "Porównanie: 2018/2017 (2017 = 100%) (grupa B)",
x = "", y = "Procentowa zmiana popularności imienia")
require(gridExtra)
grid.arrange(plot1, plot2, ncol=2)
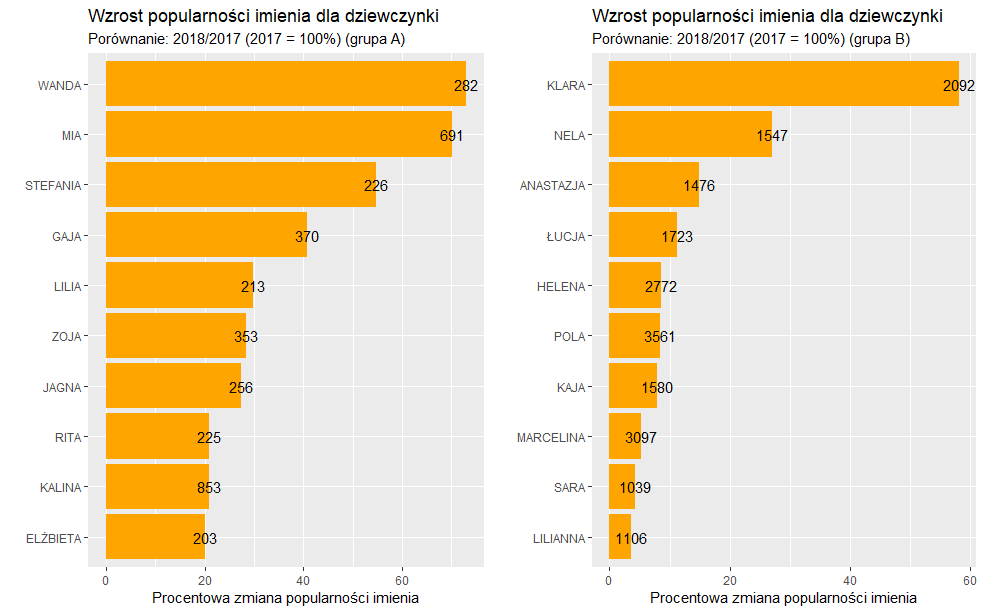
Liczby podane przy słupkach określają liczby wystąpień w 2018 roku. W grupie A największy przyrost w ilości wystąpień zanotowała Wanda (zmiana o 70% w stosunku do 2017 r.). Znaczącym wzrostem zainteresowania rodziców w nadaniu imienia cieszyła się również Stefania (wzrost o 55%) oraz Gaja (wzrost o 41%). Prawdziwym rekordzistą zmiany wśród imienia dla dziewczynek pomiędzy 2018 a 2017 rokiem w grupie B jest jednak Klara, wzrost jaki miał miejsce w tym przypadku to 58%.
Sprawdźmy także, które z imion dla dziewczynki przestało się cieszyć zwiększonych zainteresowaniem wśród przyszłych rodziców w 2018 roku.
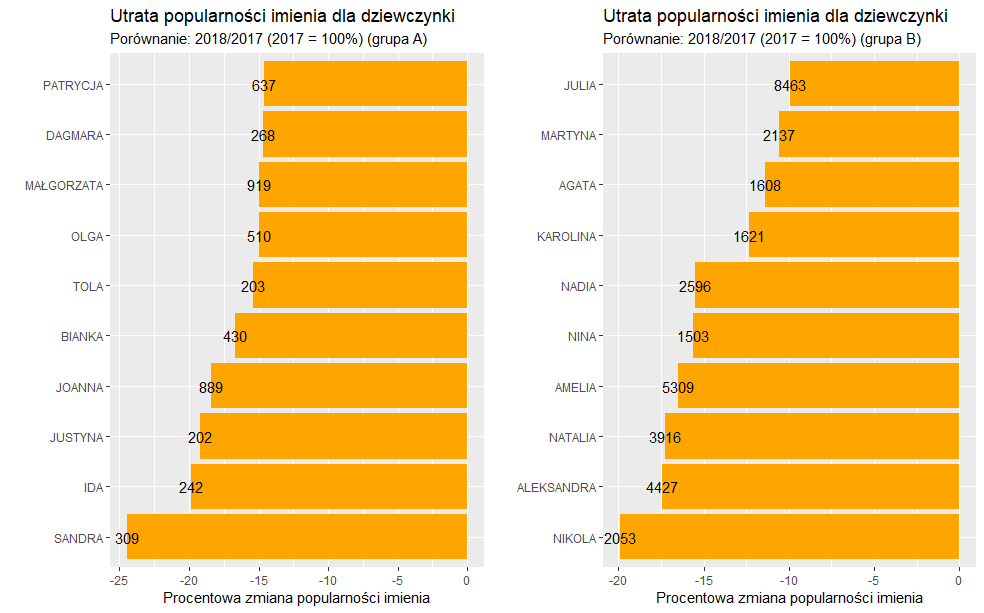
Jak widać najwięcej na popularności w grupie A straciła Sandra. Zainteresowanie tym imieniem spadło aż o 24%. Z kolei, w grupie B blisko 20% spadek miał miejsce w przypadku imienia Nikola.
W grupie imion dla chłopców sytuacja wyglądała następująco:
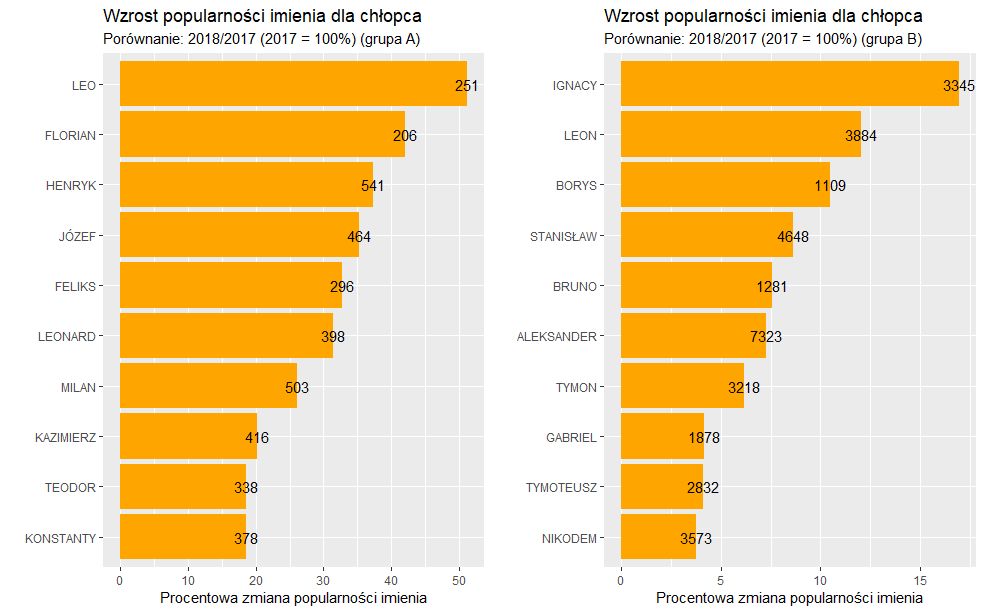
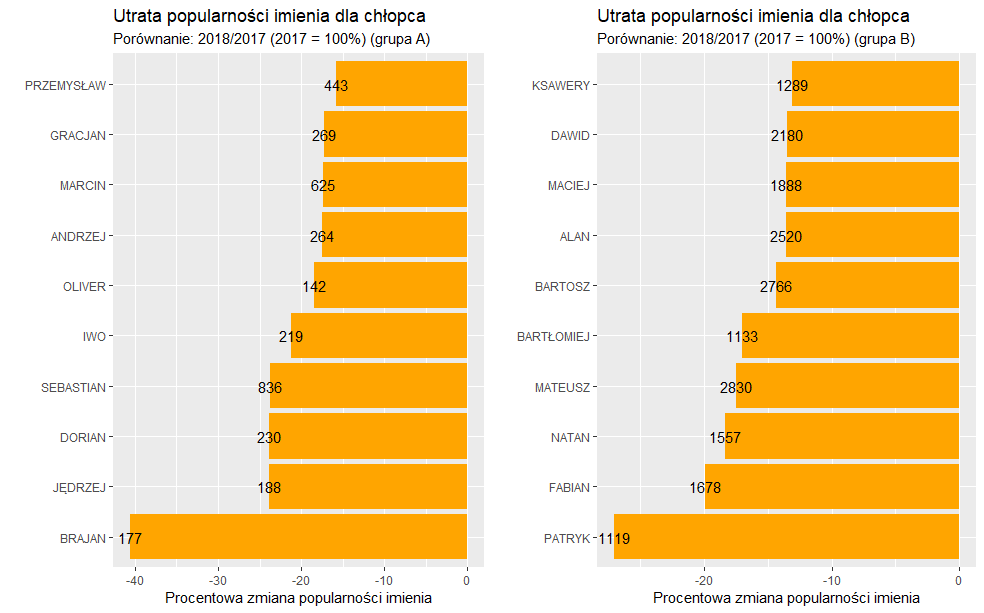
W grupie A największy wzrost odnotowano dla imienia Leo (wzrost o 51% w ilości nadania tego imienia pomiędzy rokiem 2017 a 2018). Wysoki także wzrost, powyżej 40% odnotowano dla imienia Florian. W grupie B, czyli bardziej popularnych imion największą zmianę mamy w przypadku Ignacego. Tutaj odnotowano o blisko 17% więcej nadań tego imienia w 2018r, niż w roku poprzednim. Na popularności w 2018r w grupie A stracił przede wszystkim Brajan, w 2018 r. o ponad 40% mniej nadań niż rok wcześniej. Z kolei w grupie B na „zapotrzebowanie” na imię Patryk w 2018 r. było o 27% mniejsze niż w 2017 r.
A jak wygląda sytuacja w poszczególnych województwach. Czy pomiędzy województwami występują znaczące różnice w wyborze imienia dla pociech przekonamy się po wykonaniu następującego kodu. Przy okazji wyznaczę procentowy udział danego imienia w każdym województwie na tle wszystkich imion nadanych z uwzględnieniem podziału na płeć.
imiona.df %>%
group_by(rok, plec, woj) %>%
summarise(
all = sum(liczba)
) -> imiona.rok.woj
imiona.df <- left_join(imiona.df,imiona.rok.woj,by = c('rok','plec','woj'))
imiona.df['procent'] <- imiona.df['liczba']/imiona.df['all']*100
# wybieramy top imie w kazdym województwie w danym roku
imiona.df %>%
group_by(rok, plec, woj) %>%
filter(procent == max(procent)) %>%
ungroup() %>%
select(rok, woj, plec, imie, procent) -> imiona.rok.woj.top1
I wynik zaprezentujemy na mapkach:
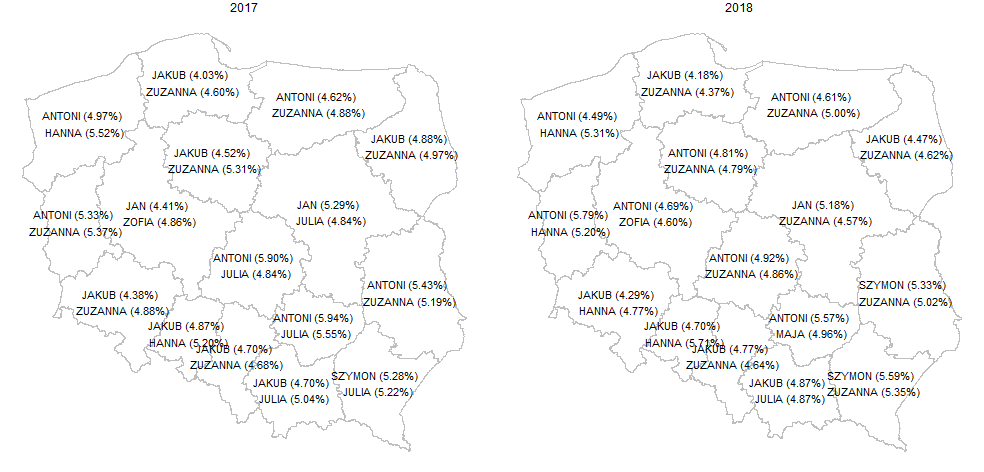
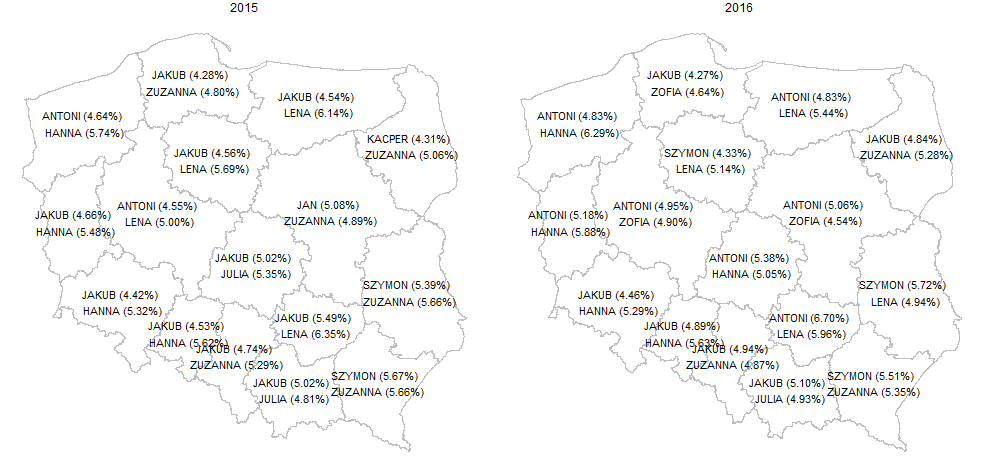
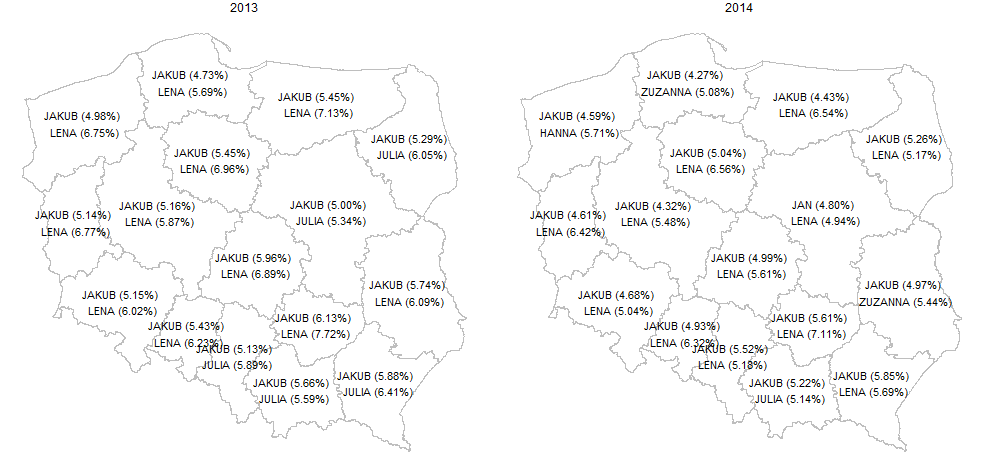
Rok 2018 to dominacja wśród imion dla dziewczynek imienia Zuzanna, praktycznie jest to najczęściej nadawane imię w środkowej i wschodniej części Polski, w zachodniej części Polski dominuje Hanna. W trzech województwach dominują inne imiona, i tak w województwie wielkopolskim najczęściej nadawanym imieniem dla dziewczynek była Zofia, w świętokrzyskim Maja, a w małopolskim Julia. Wśród imion dla chłopców obserwujemy znacznie większe zróżnicowanie terytorialne.
Gdyby prześledzić żeńskie i męskie imiona słowiańskie to łatwo zauważyć, że imiona żeńskie kończą się na literę „a”. Staropolskie mogą się jeszcze kończyć na „ć” oraz „ń”. Będzie zatem łatwo stwierdzić ile w 2018 r. nadano imion, które kończyły się na literę inną niż „a” i jaki jest to odsetek w prawie całej populacji (jak wspomniałem Ministerstwo Cyfryzacji nie podaje imion o pojedynczych wystąpieniach). Okazuje się, że ilość wystąpień wsród imion dla dziewczynek, które nie kończą się na literę „a” to 986. Zatem wśród 192714 przypadków jest to 0,5%, czyli 1 wystąpienie na 195. Najpopularniejsze żeńskie imiona to:
imiona.df %>%
filter(rok == '2018',plec == 'dziewczynek', substr(imie,nchar(imie),nchar(imie)) != "A") %>%
group_by(imie) %>%
summarise(
liczba = sum(liczba)
) %>%
arrange(desc(liczba)) %>% top_n(10) %>%
kable(col.names = c('Imię dla dziewczynki','Liczba wystąpień'),
format = "html")
| Imię dla dziewczynki | Liczba wystąpień |
|---|---|
| NEL | 213 |
| NOEMI | 111 |
| INES | 60 |
| SOPHIE | 55 |
| NICOLE | 45 |
| EMILY | 37 |
| ZOE | 36 |
| LILY | 34 |
| LILLY | 31 |
| NAOMI | 30 |
W przypadku imion dla chłopców już tak prostej zależności jak z literką „a” nie da się uchwycić. Nie mniej jednak większość imion słowiańskich męskich kończy się na spółgloskę. Zatem do dzieła, szukamy tych, które kończą się samogłoską.
vowels <- c("a","e","i","o","u","A","E","I","O","U")
imiona.df %>%
filter(rok == '2018', plec == 'chlopcow', substr(imie,nchar(imie),nchar(imie)) %in% vowels) %>%
group_by(imie) %>%
summarise(
liczba = sum(liczba)
) %>%
arrange(desc(liczba)) %>% top_n(10) %>%
kable(col.names = c('Imię dla Chłopca','Liczba wystąpień'),
format = "html")
| Imię dla chłopca | Liczba wystąpień |
|---|---|
| ANTONI | 9325 |
| BRUNO | 1281 |
| KUBA | 913 |
| MIESZKO | 395 |
| LEO | 251 |
| JEREMI | 242 |
| IWO | 219 |
| HUGO | 116 |
| MARCELI | 94 |
| KOSMA | 63 |
Wśród tej grupy są jak widać dobrze znane nam imiona słowiańskie. W dodatku na literę „a” wśród najbardziej popularnych kończących się samogłoską jest Kuba oraz Kosma.
Jurandy, gdzie się podzialiście?
I na koniec tego wpisu wprowadzę trochę prywaty by sprawdzić ile to razy w ostatnich pięciu latach nadano chłopcom imię Jurand 🙂
library(knitr)
imiona.df %>%
filter(imie == 'JURAND') %>%
select(-c(rok,plec)) %>%
kable(
col.names = c('wojewodztwo','imie','ilość','Chłopcy ogółem','Procent/Populacja chłopców'),
format = "html")

Nie powiem, wynik mnie zaskoczył. Jeżeli już któremuś z chłopców nadano imię Jurand, to jest to pojedynczy przypadek nie odnotowany w danych Ministerstwa 🙁 ze względu na ochronę danych osobowych.
To sprawdźmy jak sytuacja wygląda w przypadku imienia Igor.
imiona.df %>%
filter(rok == '2018',imie == 'IGOR') %>%
select(-c(rok,plec)) %>%
kable(
col.names = c('wojewodztwo','imie','ilość','Chłopcy ogółem','Procent/Populacja chłopców'),
format = "html")
| wojewodztwo | ilość | chłopcy ogółem | procent |
|---|---|---|---|
| dolnoslaskie | 218 | 14575 | 1.49 |
| kujawsko-pomorskie | 218 | 10761 | 2.02 |
| lubelskie | 163 | 10072 | 1.61 |
| lubuskie | 76 | 4920 | 1.54 |
| lodzkie | 213 | 12013 | 1.77 |
| malopolskie | 331 | 20467 | 1.61 |
| mazowieckie | 392 | 32245 | 1.21 |
| opolskie | 60 | 4557 | 1.31 |
| podkarpackie | 187 | 11379 | 1.64 |
| podlaskie | 98 | 6265 | 1.56 |
| pomorskie | 229 | 13651 | 1.67 |
| slaskie | 479 | 22714 | 2.10 |
| swietokrzyskie | 109 | 5276 | 2.06 |
| warminsko-mazurskie | 136 | 7324 | 1.85 |
| wielkopolskie | 371 | 20243 | 1.83 |
| zachodniopomorskie | 120 | 8302 | 1.44 |
W tym przypadku sytuacja przedstawia się odmiennie, w województwie śląskim w 2018 r. imię Igor nadano 479 chłopcom (2,10%).
Z dedykacją dla przyszłej mamy sprawdzamy jeszcze imię Bruno.
| wojewodztwo | ilość | chłopcy ogółem | procent |
|---|---|---|---|
| dolnoslaskie | 128 | 14575 | 0.8782161 |
| kujawsko-pomorskie | 56 | 10761 | 0.5203977 |
| lubelskie | 31 | 10072 | 0.3077840 |
| lubuskie | 46 | 4920 | 0.9349593 |
| lodzkie | 57 | 12013 | 0.4744860 |
| malopolskie | 102 | 20467 | 0.4983632 |
| mazowieckie | 227 | 32245 | 0.7039851 |
| opolskie | 15 | 4557 | 0.3291639 |
| podkarpackie | 36 | 11379 | 0.3163723 |
| podlaskie | 17 | 6265 | 0.2713488 |
| pomorskie | 125 | 13651 | 0.9156838 |
| slaskie | 143 | 22714 | 0.6295677 |
| swietokrzyskie | 28 | 5276 | 0.5307051 |
| warminsko-mazurskie | 36 | 7324 | 0.4915347 |
| wielkopolskie | 175 | 20243 | 0.8644964 |
| zachodniopomorskie | 59 | 8302 | 0.7106721 |
W województwie śląskim w zeszłym roku imię Bruno nadano 143 chłopcom, czyli 6 na 1000 chłopców nosi to imię. Jest zatem bardzo duża szansa że wybrane imię dla syna nie powtórzy się w grupie przedszkolnej, ani potem w szkole :).
Dodatkowe materiały
- Ministerstwo Cyfryzacji (imiona)
- Najpopularniejsze imiona w różnych krajach
- Zasady nadawania imion
- Żeńskie imiona słowiańskie
- Męskie imiona słowiańskie
Scrapping danych za rok 2018
library(rvest)
library(xml2)
library(readxl)
get_names_list <- function(url) {
#wczytanie strony
webpage <- read_html(url)
#odszukanie wezła
webpage %>% html_node("div.paragraph") -> names
#pozbycie sie znaczników
names <- gsub('<div class=\"paragraph article_section_content\"><p>|</p></div>','',names)
names <- gsub('<.{0,1}br.{0,1}>','\n',names)
#utworzenie listy imion
names <- unlist(strsplit(names,'\n ',fixed = TRUE))
#tworzymy ramkę danych z imion i nazywamy kolumny
names.df <- data.frame(do.call(rbind,strsplit(names,' - ',fixed = FALSE)))
colnames(names.df) <- c('imie','liczba')
#zamieniamy typ zmiennej imie na znak, a zmiennej liczba na liczbe // ewentulanie zostawic jako factor imie
names.df$imie <- as.character(names.df$imie)
names.df$liczba <- as.numeric(as.character(names.df$liczba))
#utworzenie dodatkowych kolumn plec i woj
plec <- sub('.*?dla-(.*?)-.*','\\1',url)
names.df['plec'] <- plec
woj <- sub('.*?woj-','\\1',url)
names.df['woj'] <- woj
names.df['rok'] <- 2018
#przekazanie ramki do funkcji wywolującej
return(names.df)
}
get_path_list <- function(url) {
#wczytanie strony
webpage <- read_html(url)
#odszukanie adresów stron
webpage %>% html_node("ul.layouts.level-1") %>%
html_nodes("li.lfr-nav-item") %>%
html_nodes("a.lfr-nav-item") %>%
html_attr("href") -> links
#tworzymy ramkę danych z adresów
links.df <- data.frame(links)
colnames(links.df) <- 'http'
#przekazanie ramki z adresami
return(links.df)
}
url <- "https://www.gov.pl/web/cyfryzacja/imiona"
# zbieramy adresy do stron
adresy <- get_path_list(url)
# utworzenie ramki z imionami
imiona.2018.df <- data.frame()
# zbieramy imiona z wojewodztw (ogolnopolski pomijamy)
for (i in 1:nrow(adresy)) {
if ( !grepl('nopolski',as.character(adresy[i,'http'])) ) {
tm.df <- get_names_list(as.character(adresy[i,'http']))
imiona.2018.df <- rbind(imiona.2018.df,tm.df)
}
}
imiona.2018.df <- imiona.2018.df %>% select(rok,woj,plec,imie,liczba)

